SELECT:
The SELECT statement is used to retrieve the data from one or more tables in a database. The basic use of SELECT statement is as follows:

The asterisk (*) is a shortcut to SELECT all columns in a table.
Note on using SELECT (*)
Using (*) is considered a bad practices for several reasons:
In normal case, you do not really need all the columns for that, we can display only the columns you need.
Use SQL Server Management Studio to generate SELECT Statement.
Navigate to database and then select the Table. Right click on the table will open the Context Menu with different options. Refer below path.
(Right click on table –> Script Table as –> SELECT To –> New Query Editor Window)
Now you can see select query in query editor window as follows.
SQL SELECT query works in a specific way i.e. it defines what is to fetch (column_list) and from where this data is to be fetch (tables).

Basic SELECT statement syntax –
SELECT column_list FROM table_name
[WHERE clause]
[GROUP BY clause]
[HAVING clause]
[ORDER BY clause]
NOTE: – SELECT and FROM clause are mandatory in SQL select queries whereas other clauses written in square [] brackets are optional.
SELECT clause – Specifies column(s) to be displayed.
FROM clause – Specifies the table which contains all the data in columns and rows format.
Tips and Tricks:-
DISTINCT clause is used to remove the duplicate records from result set, The DISTINCT clause is used only with SELECT statement.
TOP Clause:
Most of the time in real life, we try to find the top three scores in a class, the top five runners in a marathon, or the top 10 goals of the month. SQL server has a feature to select the TOP n records from a table.
We can retrieve the TOP n records from a table without using a WHERE clause. TOP can also be used with DML statements such as Update and Delete. Most of the time, TOP is used with an Order by clause to sort the results first in ascending or descending order and then to fetch the TOP n records. An order by clause with TOP makes sure we have sorted the data from a table.
TOP is used as a row limiter in SQL server just like LIMIT in Mysql.
Let’s take a look at an example of TOP used in a table.Create Table SSCResults ( Id INT IDENTITY(1,1) PRIMARY KEY, Name VARCHAR(100), Score NUMERIC(18,2) ); INSERT INTO SSCResults VALUES ('Shailesh A',98.0); INSERT INTO SSCResults VALUES ('Atul K',90.0); INSERT INTO SSCResults VALUES ('Vishal P',89.0); INSERT INTO SSCResults VALUES ('Naryan N',88.0); INSERT INTO SSCResults VALUES ('Rohit G',88.0); INSERT INTO SSCResults VALUES ('Varsha K',85.0); INSERT INTO SSCResults VALUES ('Sangram K',83.0); INSERT INTO SSCResults VALUES ('Vish K',79.0); SELECT * FROM SSCResults;

Example 1 – Selecting TOP n Records in SQL Server: Find the top three scorers in a SSCResults table
A quick way to find this is to sort the Score column in descending order and select the top three records.SELECT TOP 3 * FROM SSCResults ORDER BY Score DESC
The query above has sorted the Score field from the highest score to the lowest score first, and then it has selected the top three scores. SELECT * indicates we want to retrieve all the columns from the SSCResults table.

Example 2 – Top with Ties: Dealing with tied values
When we query the SSCResults table, we see Id = 4 and Id = 5 have the same score. In this case, if I fetch the top four records from the SSCResults table based on the Score column, Id = 5 would not show up in the list because the Top 4 records condition is not set up to handle a tie scenario.
Let’s query the top four records from the SSCResults table.SELECT TOP 4 * FROM SSCResults
We did not see that Id = 5 has the same score as Id = 4 in the results above because we did not handle a tie scenario. To get the Id = 5 record, we need to use TOP with TIES.SELECT TOP 4 WITh TIES * FROM SSCResults ORDER BY Score DESC

Top Clause with Update and Delete Statements
Example 3 – Updating Top 3 Records in a Table: Update the top three records in a table
Let’s update the score of the top 3 scorers by 0.5 percent.
We cannot use Order by directly with an Update statement. We need to use a subquery to select the top three records and then update.update SSCResults set Score = Score + 0.5 where ID in (select top 3 ID from SSCResults order by score desc);
The query above will execute the subquery first to select the top three ids (top three scorers), and then it will update their scores by adding 0.5 percent.select * from SSCResults order by score desc
We can see that the top three scores’ percents have been updated by 0.5 percent.
Example 4 – Deleting the Top 3 Records in a Table: Delete the three lowest scores from the tableDELETE FROM SSCResults where ID in (select top 3 ID from SSCResults order by score ASC);
First, the subquery will fetch the lowest scores from the table SSCResults, and an outer query will delete these records based on the ID produced by the subquery.

SQL Server 2012: Using Top with Percent in SQL Server
The TOP clause in SQL Server is used to limit the number of rows in a result set. You can specify the number of rows or percentage of rows to be returned with the TOP clause.
Specifying the percentage of rows with the TOP clause is a newly introduced feature in SQL Server 2012.
We will demonstrate TOP with Percentage.
Create a table COMPANY, and populate it with ten rows.IF OBJECT_ID('COMPANY') IS NOT NULL DROP TABLE COMPANY GO CREATE TABLE COMPANY ( ID INT PRIMARY KEY, NAME VARCHAR(25), LOCATION VARCHAR(25) ) GO INSERT INTO COMPANY VALUES (1,'HCL','London'), (2,'HP','Bangalore'), (3,'Microsoft','Bangalore'), (4,'Infosys','Pune'), (5,'Google','London'), (6,'GE', 'London'), (7,'AltiSource','New York'), (8,'Facebook','Palo alto'), (9,'IBM','New York'), (10,'TCS','Mumbai') GO
Now, we have COMPANY table with ten rows.-- Select 100 PERCENT ROWS SELECT TOP (100) PERCENT * FROM COMPANY
TOP 100 Percent gives us all the rows from company table.-- Select 50 PERCENT ROWS SELECT TOP (50) PERCENT * FROM COMPANY
We have ten rows in company table, and 50 percent of ten rows is five. Therefore, we have five rows in the result.-- Select 25 PERCENT ROWS SELECT TOP (25) PERCENT * FROM COMPANY
There are ten rows in company table, and 25 percent of ten rows is a fractional value of 2.5. It is rounded to three. Therefore, the above query returns three rows.-- Variable with TOP PERCENTAGE Declare @Percentage AS int = 30 SELECT TOP (@Percentage) PERCENT * FROM COMPANY
There are ten rows in company table, and 30 percent of ten rows is three. Therefore, we have three rows in the result.-- Select -100 PERCENT ROWS, using a Negative value which results in an Error. SELECT TOP (-100) PERCENT * FROM COMPANY
This gives the error “Percent values must be between 0 and 100,” so negative values are not allowed with TOP with Percentage.
WITH TIES Clause
If we need TOP n records from a table with ORDER BY a columns we are using this syntax
SELECT TOP n [Column Name 1], [Column Name 2] ...
FROM [Table Name]
ORDER BY [Column Name]
But we have some problem with this.
If the Table have the multiple records with same value. Only one value is selected in this case.
To understand it properly let's take an example
Step-1 [ Create The Base Table ]
-- The Base Table
IF OBJECT_ID('tbl_Example') IS NOT NULL
BEGIN
DROP TABLE tbl_Example;
END
GO
CREATE TABLE tbl_Example
(CategoryName VARCHAR(50) NOT NULL,
CategoryValue DECIMAL(10,0) NOT NULL);
GO
Step-2 [ Insert Some records ]
INSERT INTO tbl_Example
(CategoryName, CategoryValue)
VALUES ('CAT-1', 10),
('CAT-2', 10),
('CAT-3', 10),
('CAT-4', 20),
('CAT-5', 20),
('CAT-6', 30),
('CAT-7', 30),
('CAT-8', 30),
('CAT-9', 30),
('CAT-10', 30),
('CAT-11', 40)
Step-3 [ Now make the Query with TOP 1 ]
SELECT TOP 1 CategoryName, CategoryValue
FROM tbl_Example
ORDER BY CategoryValue
Output:
CategoryName CategoryValue
CAT-2 10
If we look at the output only one record is selected. But Category Value 10 is exists for 3 records in the base table.
How to Solve it
To solve this problem we use WITH TIES after TOP n clause.
SELECT TOP 1 WITH TIES CategoryName, CategoryValue
FROM tbl_Example
ORDER BY CategoryValue
Now look at the output:
CategoryName CategoryValue
CAT-1 10
CAT-2 10
CAT-3 10
Now all the three records will display.
WHERE clause in SQL is used for selective retrieval of rows from the table(s) i.e. output rows are fetched according to specific criteria (search condition). In SELECT statement, WHERE clause follows FROM clause and is used to specify the search condition. If the given search condition is satisfied then only it returns specific rows from the table(s). It acts as a filter so as to fetch only the required necessary rows.
Basic syntax for the WHERE clause –
SELECT column_list
FROM table_name
WHERE [search_condition]
Practice Section for WHERE clause : –
SELECT emp_id,emp_name,salary
FROM employee
WHERE salary > 30000
Tip 1. If you use LIKE in your WHERE clause, try to use one or more leading character in the clause, if at all possible.
Explanation :- If you use a leading character in your LIKE clause, then the Query Optimizer has the ability to potentially use an index to perform the query, speeding performance and reducing the load on SQL engine. But if the leading character in a LIKE clause is a wildcard, the Query Optimizer will not be able to use an index, and a table scan must be run, reducing performance and taking more time.
The more leading characters you can use in the LIKE clause, the more likely the Query Optimizer will find and use a suitable index.
What not to use:- LIKE ‘%Server’
What to use:- LIKE ‘SQL%’
Tip 2. When you have a choice of using the IN or the BETWEEN clauses use the BETWEEN clause, as it is much more efficient.
Explanation :– Query Optimizer can locate a range of numbers much faster (using BETWEEN) than it can find a series of numbers using the IN clause
SELECT emp_number, emp_name FROM phpring_employee WHERE emp_number in (1, 2, 3, 4, 5); is much less efficient than
SELECT emp_number, emp_name FROM phpring_employee WHERE emp_number BETWEEN 1 and 5;
Tip 3. Use of text functions in a WHERE clause hurts performance.
Explanation – Incase your database has case-sensitive data then you can go with the following to increase the efficiency and will run the query faster
What not to use :- SELECT column_name FROM table_name WHERE LOWER(column_name) = ‘name’;
What to use :- SELECT column_name FROM table_name WHERE column_name = ‘NAME’ or column_name = ‘name’;
WHERE clause can be implemented by number of ways depending upon the scenario. It is necessary to include a WHERE clause in your SELECT statement to narrow the number of rows returned. If you don’t use a WHERE clause, then SQL Server will perform a table scan of your table and return all rows.
The WHERE clause is used to restrict the number of rows returned by SELECT statement, in this case SELECT statement return the rows only if the condition specified in the WHERE clause is satisfied.
Syntax:
SELECT col1, col2, colN
FROM TableName
WHERE [conditions]
Consider the Person table without using WHERE Clause:SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person]

This query will return 19972 rows
Now, we will filter the row in with First Name as ‘Ken’, we will proceed as follows:SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person] WHERE [FirstName]='Ken'

This query will return only 6 rows
In previous example we have used WHERE clause with one condition, now we will use WHERE clause with more than one condition.
Suppose we want to display people whose first name is equal to ‘Ken’ and last name is equal to ‘Kwok’, we will proceed as follows: SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person] WHERE FirstName='Ken' AND LastName='Kwok'
And we will get one record in output as shown below.

Note:
Do not use ALIAS in the WHERE clause because the WHERE clause is evaluated before the select, so if you try something like that you will get an error as shown below.SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[FirstName] +' '+ [LastName] AS [Full Name] FROM [Person].[Person] WHERE [Full Name]='Ken Kwok'

The logical query processing is different to the conceptual interpretation order, it starts with the FROM clause, that is why it did not recognized ALIAS in the WHERE clause.
--Order the result set by TotalListPrice in ascending order
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
ORDER BY TotalListPrice ASC
--Order the result set by TotalListPrice in descending order
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
ORDER BY TotalListPrice DESC
--Order the result set by TotalListPrice in dscending then by Size in descending and then by Color ascending
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
ORDER BY TotalListPrice DESC, Size DESC, Color ASC
--List of products order by product name, default in ascending order
SELECT Name
FROM Production.Product
ORDER BY Name
--List of products order by product ID, default in ascending order
SELECT ProductID, Name AS ProductName
FROM Production.Product
ORDER BY ProductID
--List of products order by color in descending order then by product name in ascending order by default
SELECT Color, Name AS ProductName
FROM Production.Product
ORDER BY Color DESC, ProductName
To sort the result set with a column in ascending or descending order, we use ASC and DESC keywords with ORDER BY clause which defaults to ascending (ASC). That is, if we omit the ASC or DESC keyword after ORDER BY, by default, it is ASC.
Returns true if a specified value matches any value in a sub query or a list.
EXISTS Clause
Returns true if a sub query contains any rows.
So we see that the "IN" and the "EXISTS" clause are not same. To support the above definition lets takes an example.
-- Base Tabe
IF OBJECT_ID('emp_DtlTbl') IS NOT NULL
BEGIN
DROP TABLE emp_DtlTbl;
END
GO
IF OBJECT_ID('emp_GradeTbl') IS NOT NULL
BEGIN
DROP TABLE emp_GradeTbl;
END
GO
CREATE TABLE emp_DtlTbl
(EMPID INT NOT NULL IDENTITY PRIMARY KEY,
EMPNAME VARCHAR(50)NOT NULL);
GO
CREATE TABLE emp_GradeTbl
(EMPID INT NOT NULL IDENTITY PRIMARY KEY,
GRADE VARCHAR(1) NOT NULL);
GO
-- Insert Records
INSERT INTO emp_DtlTbl
(EMPNAME)
VALUES ('Joydeep Das'), ('Sukamal Jana'), ('Sudip Das');
GO
INSERT INTO emp_GradeTbl
(GRADE)
VALUES ('B'), ('B'), ('A');
GO
-- [ IN ] Clause Example-1
SELECT *
FROM emp_DtlTbl;
WHERE EMPID IN(SELECT EMPID FROM emp_DtlTbl);
-- [ IN ] Clause Example-2
SELECT *
FROM emp_DtlTbl
WHERE EMPID IN(1,2,3);
-- [ EXISTS ] Clause Example
SELECT a.*
FROM emp_DtlTbl a
WHERE EXISTS(SELECT b.*
FROM emp_DtlTbl b
WHERE b.EMPID = a.EMPID);
Performance Factors
To understand the performance factors let see the actual execution plan for "IN" and "EXISTS" clauses.
Take this example:
-- [ IN ] Clause Example
SELECT *
FROM emp_DtlTbl
WHERE EMPID =(SELECT EMPID
FROM emp_DtlTbl
WHERE EMPID = 2);
-- [ EXISTS ] Clause Example
SELECT a.*
FROM emp_DtlTbl a
WHERE EXISTS(SELECT b.*
FROM emp_DtlTbl b
WHERE b.EMPID = 2
AND b.EMPID = a.EMPID);
If we compare the total query costs of the both MS SQL query, we see that the IN clause query cost is higher than the EXISTS clause query costs.
Special notes
Please note that: Here the data of the table is limited, so we cannot measure the performance factors.
Usage of OVER Clause
SELECT INTO
The SQL Server (Transact-SQL) SELECT INTO statement is used to create a table from an existing table by copying the existing table's columns.
Syntax:
SELECT Column(S) INTO NewTableName FROM TableName
SELECT * INTO NewTableName FROM TableName
If you want to create only structure of table the follow the below syntax:
SELECT * INTO NewTableName FROM TableName WHERE 1=0
BETWEEN Clause Vs [ >= AND <= ]
In this article I am trying to discuss related to BETWEEN clause and >= AND <= comparisons operators and which one is best.
What is the Difference
Let's take an example to understand it properly.
Step-1 [ Create the Base Table ]
CREATE TABLE my_TestTab
(ID INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
VAL DATETIME NOT NULL);
Step-2 [ Inserting Records ]
INSERT INTO my_TestTab
(VAL)
VALUES('05-01-2012'),
('05-07-2012'),
('05-11-2012'),
('05-15-2012'),
('05-22-2012'),
('05-23-2012'),
('05-25-2012'),
('05-27-2012'),
('05-28-2012');
Step-3 [ Now use Between Clause ]
SELECT *
FROM my_TestTab
WHERE VAL BETWEEN '05-01-2012' AND '05-28-2012';
Output:
ID VAL
1 2012-05-01 00:00:00.000
2 2012-05-07 00:00:00.000
3 2012-05-11 00:00:00.000
4 2012-05-15 00:00:00.000
5 2012-05-22 00:00:00.000
6 2012-05-23 00:00:00.000
7 2012-05-25 00:00:00.000
8 2012-05-27 00:00:00.000
9 2012-05-28 00:00:00.000
Step-4 [ Now using >= AND <= ]
SELECT *
FROM my_TestTab
WHERE VAL >='05-01-2012' AND VAL<='05-28-2012';
Output:
ID VAL
1 2012-05-01 00:00:00.000
2 2012-05-07 00:00:00.000
3 2012-05-11 00:00:00.000
4 2012-05-15 00:00:00.000
5 2012-05-22 00:00:00.000
6 2012-05-23 00:00:00.000
7 2012-05-25 00:00:00.000
8 2012-05-27 00:00:00.000
9 2012-05-28 00:00:00.000
To observe the difference between Step-3 and Step-4 just execute the SQL of Step-3 Again and see the actual execution plan.
SELECT *
FROM my_TestTab
WHERE VAL BETWEEN '05-01-2012' AND '05-28-2012';

If we see the execution plan we find that
SELECT * FROM my_TestTab WHERE [VAL] >= @1 AND [VAL]<=@2
So there is no difference between Step-3 and Step-4. Actually internally the BETWEEN clause is converted to >= and <= logical operators.
Summary
As per me using BETWEEN clause is much easier then the >= and <= operators and it looks great in complex query.
It actually depends on developer and there writing style of T-SQL.
Commenting code in T-SQL:
In T-SQL, we can use double hyphens (–) to comment a single line of code (as we did in the above example code) and to comment multiple line at once we can simply enclose the codes between (/* and */) as:
/*Commented code goes here*/
SELECT 'Welcome to t-sql programming' AS [Column1]
<aggregate-filter> Aggregate filter applies to aggregated data unlike “WHERE” which filters the data while reading from the table. We can use aggregated filters with the aggregated result set. E.g. HAVING COUNT(column-name-1) > 10.
The SELECT statement is used to retrieve the data from one or more tables in a database. The basic use of SELECT statement is as follows:
Syntax:
SELECT * FROM TableName – (To select all columns)
or
SELECT col1, col2,colN FROM TableName – (To select specific columns)
SELECT * FROM TableName – (To select all columns)
or
SELECT col1, col2,colN FROM TableName – (To select specific columns)
or
SELECT DISTINCT column1, column2, FROM table_name - (SELECT unique/distinct columns example)
It can fetch data from a single table, or from multiple tables using JOIN, UNION, INTERSECTION and EXCEPT.
<column-list> is the comma separated list of required columns in the output. E.g. SELECT [column-name-1], [column-name-2], [column-name-3] ……[column-name-n].
<column-list> is the comma separated list of required columns in the output. E.g. SELECT [column-name-1], [column-name-2], [column-name-3] ……[column-name-n].
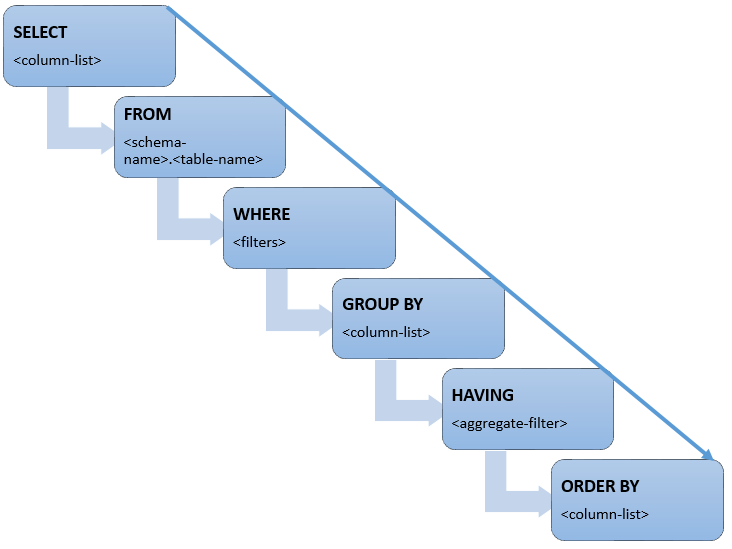
SELECT statement can have FROM, WHERE, GROUP BY, HAVING and ORDER BY clauses or it can just have a few of them but in below specified order only. If a clause is not required, we can skip it in SELECT statement, but we cannot change the order in which they are used. We can correlate this with a stair in which we can jump some steps, but we cannot change the order of the steps of the stair. Have a look on below image:
The asterisk (*) is a shortcut to SELECT all columns in a table.
Note on using SELECT (*)
Using (*) is considered a bad practices for several reasons:
- Often you do not need all the columns, but with the use of (*) you display them all, which will increase load on database server and impact the performance.
- If you make a change to a table, adding or removing columns, this change does not reflect the views created with the use of (*).
- You can not change the order of selected columns.
We should use the name of each column explicitly in the query even if all the columns are required in the result set because if a column name gets changed, we get the error at the time of query execution which does not occur in case of asterisk (*). As asterisk fetches all the current column names of the table, any change in column names would lead to an error at application level.
Select Specific ColumnsIn normal case, you do not really need all the columns for that, we can display only the columns you need.
Use SQL Server Management Studio to generate SELECT Statement.
Navigate to database and then select the Table. Right click on the table will open the Context Menu with different options. Refer below path.
(Right click on table –> Script Table as –> SELECT To –> New Query Editor Window)
Now you can see select query in query editor window as follows.
SQL SELECT query works in a specific way i.e. it defines what is to fetch (column_list) and from where this data is to be fetch (tables).

Basic SELECT statement syntax –
SELECT column_list FROM table_name
[WHERE clause]
[GROUP BY clause]
[HAVING clause]
[ORDER BY clause]
NOTE: – SELECT and FROM clause are mandatory in SQL select queries whereas other clauses written in square [] brackets are optional.
SELECT clause – Specifies column(s) to be displayed.
FROM clause – Specifies the table which contains all the data in columns and rows format.
Mind the square brackets surrounding the name of the columns. Enclose column names in between square brackets if the column name contains any space or is a SQL keyword otherwise using square brackets is optional.
We all know that SQL is not a case sensitive language like java, ASP.NET, etc. It means our “SELECT” will display the same result as displayed by “select” in the query.
We all know that SQL is not a case sensitive language like java, ASP.NET, etc. It means our “SELECT” will display the same result as displayed by “select” in the query.
Remember, we can rename any column in output result set using ASclause.
SQL Tips with OUTPUT options
This is a simple statement basically the Insert and delete.
When we insert or delete records from table objects, it shows number of rows affected. But we want to know how what the values of the row that is effected for Insert or delete statement.
As you know that there are 2 table named Inserted and deleted who take the information related to insert and delete, using this there is a simple steps that shows what's actually going on when insert and delete statements fires.
Step-1 [ Just Create the table objects ]
IF NOT EXISTS(SELECT * FROM sys.sysobjects WHERE xtype='U' ANDname='TestTable')
BEGIN
CREATE TABLE TestTable
(Roll DECIMAL(1) NOT NULLIDENTITY(1,1) PRIMARY KEY,
Sname VARCHAR(50) NOT NULL,
Class DECIMAL(1) NULL,
Section VARCHAR(1))
END
GO
Step-2 [ Now fire some insert statement like this ]
-- Insert Statement with OUTPUT Options
INSERT INTO TestTable(Sname, Class, Section)
OUTPUT inserted.roll, inserted.sname, inserted.Class, inserted.Section
VALUES ('Tufan', 5, 'A'),('Joydeep',1,'A'),('Palash',1,'A'),('Sangram',1,'A')
It will show the output of what it inserted not the numbers of row affected.
roll sname Class Section
1 Tufan 1 A
2 Joydeep 1 A
3 Palash 1 A
4 Sangram 1 A
Step-3 Now fire the delete statement like this
DELETE TestTable
OUTPUT deleted.roll, deleted.sname, deleted.Class, deleted.Section
WHERE Roll=1
It will show the output of what it deleted not the numbers of row affected.
roll sname Class Section
1 Tufan 1 A
This is a simple statement basically the Insert and delete.
When we insert or delete records from table objects, it shows number of rows affected. But we want to know how what the values of the row that is effected for Insert or delete statement.
As you know that there are 2 table named Inserted and deleted who take the information related to insert and delete, using this there is a simple steps that shows what's actually going on when insert and delete statements fires.
Step-1 [ Just Create the table objects ]
IF NOT EXISTS(SELECT * FROM sys.sysobjects WHERE xtype='U' ANDname='TestTable')
BEGIN
CREATE TABLE TestTable
(Roll DECIMAL(1) NOT NULLIDENTITY(1,1) PRIMARY KEY,
Sname VARCHAR(50) NOT NULL,
Class DECIMAL(1) NULL,
Section VARCHAR(1))
END
GO
Step-2 [ Now fire some insert statement like this ]
-- Insert Statement with OUTPUT Options
INSERT INTO TestTable(Sname, Class, Section)
OUTPUT inserted.roll, inserted.sname, inserted.Class, inserted.Section
VALUES ('Tufan', 5, 'A'),('Joydeep',1,'A'),('Palash',1,'A'),('Sangram',1,'A')
It will show the output of what it inserted not the numbers of row affected.
roll sname Class Section
1 Tufan 1 A
2 Joydeep 1 A
3 Palash 1 A
4 Sangram 1 A
Step-3 Now fire the delete statement like this
DELETE TestTable
OUTPUT deleted.roll, deleted.sname, deleted.Class, deleted.Section
WHERE Roll=1
It will show the output of what it deleted not the numbers of row affected.
roll sname Class Section
1 Tufan 1 A
Tips and Tricks:-
- Never return column data which is not required.
- Explanation – Because by returning data you don’t need, you are causing SQL engine to perform I/O it doesn’t need to perform, wasting SQL engine resources. In addition, it increases network traffic, which can also lead to reduced Performance
- What not to use: – SELECT * FROM table_name;
- What to use: – SELECT column1, column2, clomn3 FROM table_name;
- Carefully evaluate your SELECT query whether DISTINCT clause is required or not.
- Explanation – The DISTINCT clause should only be used in SELECT statements if you know that duplicate returned rows are a possibility, and that having duplicate rows in the result set would cause problems with your application. The DISTINCT clause creates a lot of extra work for SQL Server, and reduces the physical resources that other SQL statements have at their disposal. That’s why DISTINCT clause is used if necessary.
DISTINCT:
DISTINCT clause is used to remove the duplicate records from result set, The DISTINCT clause is used only with SELECT statement.
Syntax:
SELECT DISTINCT [ColumnNames]
FROM TableName
We will start with an example, we would like to display the column CardType on table CreditCard, This will proceed as: SELECT [CardType] FROM [Sales].[CreditCard]

You’ve noticed that there are duplicates in the result.
Using DISTINCT on single column
DISTINCT clause allows us to eliminate duplicates in the result set.
SELECT DISTINCT [ColumnNames]
FROM TableName
We will start with an example, we would like to display the column CardType on table CreditCard, This will proceed as: SELECT [CardType] FROM [Sales].[CreditCard]

You’ve noticed that there are duplicates in the result.
Using DISTINCT on single column
DISTINCT clause allows us to eliminate duplicates in the result set.
SELECT DISTINCT [CardType]
FROM [Sales].[CreditCard]

Using DISTINCT on multiple columns
In the combination of multiple columns, DISTINCT eliminates the rows where all the selectedrows are identical.
SELECT DISTINCT [CardType], [ModifiedDate] FROM [Sales].[CreditCard]

Note:
In SQL Server the DISTINCT clause doesn’t ignore NULL values. So when using the DISTINCT clause use NOT NULL functions to remove NULLS.
If possible, avoid using DISTINCT because DISTINCT impacts the performances.

Using DISTINCT on multiple columns
In the combination of multiple columns, DISTINCT eliminates the rows where all the selectedrows are identical.
SELECT DISTINCT [CardType], [ModifiedDate] FROM [Sales].[CreditCard]

Note:
In SQL Server the DISTINCT clause doesn’t ignore NULL values. So when using the DISTINCT clause use NOT NULL functions to remove NULLS.
If possible, avoid using DISTINCT because DISTINCT impacts the performances.
TOP Clause:
Most of the time in real life, we try to find the top three scores in a class, the top five runners in a marathon, or the top 10 goals of the month. SQL server has a feature to select the TOP n records from a table.
We can retrieve the TOP n records from a table without using a WHERE clause. TOP can also be used with DML statements such as Update and Delete. Most of the time, TOP is used with an Order by clause to sort the results first in ascending or descending order and then to fetch the TOP n records. An order by clause with TOP makes sure we have sorted the data from a table.
TOP is used as a row limiter in SQL server just like LIMIT in Mysql.
Let’s take a look at an example of TOP used in a table.Create Table SSCResults ( Id INT IDENTITY(1,1) PRIMARY KEY, Name VARCHAR(100), Score NUMERIC(18,2) ); INSERT INTO SSCResults VALUES ('Shailesh A',98.0); INSERT INTO SSCResults VALUES ('Atul K',90.0); INSERT INTO SSCResults VALUES ('Vishal P',89.0); INSERT INTO SSCResults VALUES ('Naryan N',88.0); INSERT INTO SSCResults VALUES ('Rohit G',88.0); INSERT INTO SSCResults VALUES ('Varsha K',85.0); INSERT INTO SSCResults VALUES ('Sangram K',83.0); INSERT INTO SSCResults VALUES ('Vish K',79.0); SELECT * FROM SSCResults;
Example 1 – Selecting TOP n Records in SQL Server: Find the top three scorers in a SSCResults table
A quick way to find this is to sort the Score column in descending order and select the top three records.SELECT TOP 3 * FROM SSCResults ORDER BY Score DESC
The query above has sorted the Score field from the highest score to the lowest score first, and then it has selected the top three scores. SELECT * indicates we want to retrieve all the columns from the SSCResults table.
Example 2 – Top with Ties: Dealing with tied values
When we query the SSCResults table, we see Id = 4 and Id = 5 have the same score. In this case, if I fetch the top four records from the SSCResults table based on the Score column, Id = 5 would not show up in the list because the Top 4 records condition is not set up to handle a tie scenario.
Let’s query the top four records from the SSCResults table.SELECT TOP 4 * FROM SSCResults
We did not see that Id = 5 has the same score as Id = 4 in the results above because we did not handle a tie scenario. To get the Id = 5 record, we need to use TOP with TIES.SELECT TOP 4 WITh TIES * FROM SSCResults ORDER BY Score DESC
Top Clause with Update and Delete Statements
Example 3 – Updating Top 3 Records in a Table: Update the top three records in a table
Let’s update the score of the top 3 scorers by 0.5 percent.
We cannot use Order by directly with an Update statement. We need to use a subquery to select the top three records and then update.update SSCResults set Score = Score + 0.5 where ID in (select top 3 ID from SSCResults order by score desc);
The query above will execute the subquery first to select the top three ids (top three scorers), and then it will update their scores by adding 0.5 percent.select * from SSCResults order by score desc
We can see that the top three scores’ percents have been updated by 0.5 percent.
Example 4 – Deleting the Top 3 Records in a Table: Delete the three lowest scores from the tableDELETE FROM SSCResults where ID in (select top 3 ID from SSCResults order by score ASC);
First, the subquery will fetch the lowest scores from the table SSCResults, and an outer query will delete these records based on the ID produced by the subquery.
SQL Server 2012: Using Top with Percent in SQL Server
The TOP clause in SQL Server is used to limit the number of rows in a result set. You can specify the number of rows or percentage of rows to be returned with the TOP clause.
Specifying the percentage of rows with the TOP clause is a newly introduced feature in SQL Server 2012.
We will demonstrate TOP with Percentage.
Create a table COMPANY, and populate it with ten rows.IF OBJECT_ID('COMPANY') IS NOT NULL DROP TABLE COMPANY GO CREATE TABLE COMPANY ( ID INT PRIMARY KEY, NAME VARCHAR(25), LOCATION VARCHAR(25) ) GO INSERT INTO COMPANY VALUES (1,'HCL','London'), (2,'HP','Bangalore'), (3,'Microsoft','Bangalore'), (4,'Infosys','Pune'), (5,'Google','London'), (6,'GE', 'London'), (7,'AltiSource','New York'), (8,'Facebook','Palo alto'), (9,'IBM','New York'), (10,'TCS','Mumbai') GO
Now, we have COMPANY table with ten rows.-- Select 100 PERCENT ROWS SELECT TOP (100) PERCENT * FROM COMPANY
TOP 100 Percent gives us all the rows from company table.-- Select 50 PERCENT ROWS SELECT TOP (50) PERCENT * FROM COMPANY
We have ten rows in company table, and 50 percent of ten rows is five. Therefore, we have five rows in the result.-- Select 25 PERCENT ROWS SELECT TOP (25) PERCENT * FROM COMPANY
There are ten rows in company table, and 25 percent of ten rows is a fractional value of 2.5. It is rounded to three. Therefore, the above query returns three rows.-- Variable with TOP PERCENTAGE Declare @Percentage AS int = 30 SELECT TOP (@Percentage) PERCENT * FROM COMPANY
There are ten rows in company table, and 30 percent of ten rows is three. Therefore, we have three rows in the result.-- Select -100 PERCENT ROWS, using a Negative value which results in an Error. SELECT TOP (-100) PERCENT * FROM COMPANY
This gives the error “Percent values must be between 0 and 100,” so negative values are not allowed with TOP with Percentage.
WITH TIES Clause
If we need TOP n records from a table with ORDER BY a columns we are using this syntax
SELECT TOP n [Column Name 1], [Column Name 2] ...
FROM [Table Name]
ORDER BY [Column Name]
But we have some problem with this.
So What's the Problem
If the Table have the multiple records with same value. Only one value is selected in this case.
To understand it properly let's take an example
Step-1 [ Create The Base Table ]
-- The Base Table
IF OBJECT_ID('tbl_Example') IS NOT NULL
BEGIN
DROP TABLE tbl_Example;
END
GO
CREATE TABLE tbl_Example
(CategoryName VARCHAR(50) NOT NULL,
CategoryValue DECIMAL(10,0) NOT NULL);
GO
Step-2 [ Insert Some records ]
INSERT INTO tbl_Example
(CategoryName, CategoryValue)
VALUES ('CAT-1', 10),
('CAT-2', 10),
('CAT-3', 10),
('CAT-4', 20),
('CAT-5', 20),
('CAT-6', 30),
('CAT-7', 30),
('CAT-8', 30),
('CAT-9', 30),
('CAT-10', 30),
('CAT-11', 40)
Step-3 [ Now make the Query with TOP 1 ]
SELECT TOP 1 CategoryName, CategoryValue
FROM tbl_Example
ORDER BY CategoryValue
Output:
CategoryName CategoryValue
CAT-2 10
If we look at the output only one record is selected. But Category Value 10 is exists for 3 records in the base table.
How to Solve it
To solve this problem we use WITH TIES after TOP n clause.
SELECT TOP 1 WITH TIES CategoryName, CategoryValue
FROM tbl_Example
ORDER BY CategoryValue
Now look at the output:
CategoryName CategoryValue
CAT-1 10
CAT-2 10
CAT-3 10
Now all the three records will display.
Caution
WITH TIES is used with ORDER BY clause. If we don't use the ORDER BY clause an error is generated.
Msg 1062, Level 15, State 1, Line 2
The TOP N WITH TIES clause is not allowed without a corresponding ORDER BY clause.
WITH TIES is used with ORDER BY clause. If we don't use the ORDER BY clause an error is generated.
Msg 1062, Level 15, State 1, Line 2
The TOP N WITH TIES clause is not allowed without a corresponding ORDER BY clause.
FROM clause
The FROM clause is used to specify the name of the object from which data needs to be retrieved. The object name can be the name of a table, derived table, common table expression (CTE), view or function name.
The FROM clause is used to specify the name of the object from which data needs to be retrieved. The object name can be the name of a table, derived table, common table expression (CTE), view or function name.
WHERE clause
WHERE clause provides a way to put a filter to the table at row level while reading the data. Using appropriate WHERE clause speeds up the query by reducing the amount of data to be read from the table. Generally, we don’t need to extract all the data from a table. We need few columns which satisfy few given filter conditions.
We can combine multiple logical conditions with AND and OR logical operators as we did above. We will cover logical operators in more detail later in this tutorial.
WHERE clause provides a way to put a filter to the table at row level while reading the data. Using appropriate WHERE clause speeds up the query by reducing the amount of data to be read from the table. Generally, we don’t need to extract all the data from a table. We need few columns which satisfy few given filter conditions.
We can combine multiple logical conditions with AND and OR logical operators as we did above. We will cover logical operators in more detail later in this tutorial.
WHERE clause in SQL is used for selective retrieval of rows from the table(s) i.e. output rows are fetched according to specific criteria (search condition). In SELECT statement, WHERE clause follows FROM clause and is used to specify the search condition. If the given search condition is satisfied then only it returns specific rows from the table(s). It acts as a filter so as to fetch only the required necessary rows.
Basic syntax for the WHERE clause –
SELECT column_list
FROM table_name
WHERE [search_condition]
Practice Section for WHERE clause : –
SELECT emp_id,emp_name,salary
FROM employee
WHERE salary > 30000
--To get the list of all black color products
SELECT
ProductID, Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice
FROM Production.Product
WHERE Color = 'Black'
--To get the list of all black color products with list price greater than 50
SELECT
ProductID, Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice
FROM Production.Product
WHERE Color = 'Black' AND ListPrice > 50
--To get the list of all black or blue color products
SELECT
ProductID, Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice
FROM Production.Product
WHERE Color = 'Black' OR Color = 'Blue'
Tips and Trics for WHERE clause :-
SELECT
ProductID, Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice
FROM Production.Product
WHERE Color = 'Black'
--To get the list of all black color products with list price greater than 50
SELECT
ProductID, Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice
FROM Production.Product
WHERE Color = 'Black' AND ListPrice > 50
--To get the list of all black or blue color products
SELECT
ProductID, Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice
FROM Production.Product
WHERE Color = 'Black' OR Color = 'Blue'
Tips and Trics for WHERE clause :-
Tip 1. If you use LIKE in your WHERE clause, try to use one or more leading character in the clause, if at all possible.
Explanation :- If you use a leading character in your LIKE clause, then the Query Optimizer has the ability to potentially use an index to perform the query, speeding performance and reducing the load on SQL engine. But if the leading character in a LIKE clause is a wildcard, the Query Optimizer will not be able to use an index, and a table scan must be run, reducing performance and taking more time.
The more leading characters you can use in the LIKE clause, the more likely the Query Optimizer will find and use a suitable index.
What not to use:- LIKE ‘%Server’
What to use:- LIKE ‘SQL%’
Tip 2. When you have a choice of using the IN or the BETWEEN clauses use the BETWEEN clause, as it is much more efficient.
Explanation :– Query Optimizer can locate a range of numbers much faster (using BETWEEN) than it can find a series of numbers using the IN clause
SELECT emp_number, emp_name FROM phpring_employee WHERE emp_number in (1, 2, 3, 4, 5); is much less efficient than
SELECT emp_number, emp_name FROM phpring_employee WHERE emp_number BETWEEN 1 and 5;
Tip 3. Use of text functions in a WHERE clause hurts performance.
Explanation – Incase your database has case-sensitive data then you can go with the following to increase the efficiency and will run the query faster
What not to use :- SELECT column_name FROM table_name WHERE LOWER(column_name) = ‘name’;
What to use :- SELECT column_name FROM table_name WHERE column_name = ‘NAME’ or column_name = ‘name’;
WHERE clause can be implemented by number of ways depending upon the scenario. It is necessary to include a WHERE clause in your SELECT statement to narrow the number of rows returned. If you don’t use a WHERE clause, then SQL Server will perform a table scan of your table and return all rows.
The WHERE clause is used to restrict the number of rows returned by SELECT statement, in this case SELECT statement return the rows only if the condition specified in the WHERE clause is satisfied.
Syntax:
SELECT col1, col2, colN
FROM TableName
WHERE [conditions]
Consider the Person table without using WHERE Clause:SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person]

This query will return 19972 rows
Now, we will filter the row in with First Name as ‘Ken’, we will proceed as follows:SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person] WHERE [FirstName]='Ken'

This query will return only 6 rows
In previous example we have used WHERE clause with one condition, now we will use WHERE clause with more than one condition.
Suppose we want to display people whose first name is equal to ‘Ken’ and last name is equal to ‘Kwok’, we will proceed as follows: SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] FROM [Person].[Person] WHERE FirstName='Ken' AND LastName='Kwok'
And we will get one record in output as shown below.

Note:
Do not use ALIAS in the WHERE clause because the WHERE clause is evaluated before the select, so if you try something like that you will get an error as shown below.SELECT [BusinessEntityID] ,[PersonType] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[FirstName] +' '+ [LastName] AS [Full Name] FROM [Person].[Person] WHERE [Full Name]='Ken Kwok'

The logical query processing is different to the conceptual interpretation order, it starts with the FROM clause, that is why it did not recognized ALIAS in the WHERE clause.
GROUP BY clause
GROUP BY clause is used to summarize the result set by one or more columns. It aggregates the data as per the available values in columns. Lets have a few sample queries to make it clear:
--Query 1
--ListPrice total for all Black and Blue color products
SELECT
Color, SUM(ListPrice) AS TotalListPrice
FROM Production.Product
WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color
--Query 2
--Size wise ListPrice total for all Black and Blue color products
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
In the above example, in Query 1, ListPrice is summed and color column values are grouped to summarize the outcome of query by color. We get only two rows, one for black and another for blue color, though we have many rows of black and blue color in the Product table. The result set has been aggregated by color which we have in the group by clause. In Query 2, the result set is grouped by Color and Size whereas ListPrice is summed.

Group By clause example
We cannot have a non aggregated column with an aggregated column in select list. Either we can have all aggregated columns or there should not be an aggregation on any column. For example, if we have column1 and column2 in the select list and grouping the result set by column1 only, it would raise an error. We can resolve the error either by putting both columns column1 and column2 in the group by clause or by removing both columns from the group by clause.
GROUP BY clause is used to summarize the result set by one or more columns. It aggregates the data as per the available values in columns. Lets have a few sample queries to make it clear:
--Query 1
--ListPrice total for all Black and Blue color products
SELECT
Color, SUM(ListPrice) AS TotalListPrice
FROM Production.Product
WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color
--Query 2
--Size wise ListPrice total for all Black and Blue color products
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
In the above example, in Query 1, ListPrice is summed and color column values are grouped to summarize the outcome of query by color. We get only two rows, one for black and another for blue color, though we have many rows of black and blue color in the Product table. The result set has been aggregated by color which we have in the group by clause. In Query 2, the result set is grouped by Color and Size whereas ListPrice is summed.

Group By clause example
We cannot have a non aggregated column with an aggregated column in select list. Either we can have all aggregated columns or there should not be an aggregation on any column. For example, if we have column1 and column2 in the select list and grouping the result set by column1 only, it would raise an error. We can resolve the error either by putting both columns column1 and column2 in the group by clause or by removing both columns from the group by clause.
GROUP BY Clause And Performance Factors
In this article I am trying to describe the frequently used GROUP BY Clause and the Performance factor related to it.
A short description of GROUP BY Clause
The GROUP BY clause can be used in a SELECT statement to collect data across multiple records and group the results by one or more columns. The aggregate function columns are not included in GROUP BY cluse, I mean to say the columns that used the aggregate function is not included in the GROUP BY cluse.
The HAVING cluse is used to filters the GROUP BY cluse.
Example:
SELECT columns1, columns2, SUM(columns3)
FROM Mytable
GROUP BY columns1, columns2
HAVING columns1>0
Is the GROUP BY is the Performance killer?
NO the GROUP BY itself is not the performance killer.
In many cases the GROUP BY clause dramatically decreases the performance of the Query.
Here are the some points to take care:
1. To make the performance better, use the COMPOUND INDEXES for the GROUP BY fields.
2. Don't use unnecessary fields or Unnatural Grouping options.
3. I personally preferred the same sequence of columns in SELECT as well as GROUP BY. For
In this article I am trying to describe the frequently used GROUP BY Clause and the Performance factor related to it.
A short description of GROUP BY Clause
The GROUP BY clause can be used in a SELECT statement to collect data across multiple records and group the results by one or more columns. The aggregate function columns are not included in GROUP BY cluse, I mean to say the columns that used the aggregate function is not included in the GROUP BY cluse.
The HAVING cluse is used to filters the GROUP BY cluse.
Example:
SELECT columns1, columns2, SUM(columns3)
FROM Mytable
GROUP BY columns1, columns2
HAVING columns1>0
Is the GROUP BY is the Performance killer?
NO the GROUP BY itself is not the performance killer.
In many cases the GROUP BY clause dramatically decreases the performance of the Query.
Here are the some points to take care:
1. To make the performance better, use the COMPOUND INDEXES for the GROUP BY fields.
2. Don't use unnecessary fields or Unnatural Grouping options.
3. I personally preferred the same sequence of columns in SELECT as well as GROUP BY. For
Example.
Like this:
SELECT columns1, columns2, SUM(columns3)
FROM Mytable
GROUP BY columns1, columns2
Not Like this:
SELECT columns1, columns2, SUM(columns3)
FROM Mytable
GROUP BY columns2, columns1
This is a small article, but I hope it is quite informative and thanking you to provide your valuable time on it.
Like this:
SELECT columns1, columns2, SUM(columns3)
FROM Mytable
GROUP BY columns1, columns2
Not Like this:
SELECT columns1, columns2, SUM(columns3)
FROM Mytable
GROUP BY columns2, columns1
This is a small article, but I hope it is quite informative and thanking you to provide your valuable time on it.
HAVING clause
HAVING clause is used to put a filter on aggregated or grouped data. If we want to list only those colors whose sum of ListPrice is more than 3000, use HAVING clause.
Having clause is more resource intensive than WHERE clause as we need to read all the data, aggregate it, then apply a filter unlike WHERE clause which filters the data at row level and reduces the I/O by reading less data. But, sometimes we need to filter aggregated date instead of row level as like below query.
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
Above query outcomes all the rows grouped by color and size, which have the sum of ListPrice greater than 3000.
HAVING clause is used to put a filter on aggregated or grouped data. If we want to list only those colors whose sum of ListPrice is more than 3000, use HAVING clause.
Having clause is more resource intensive than WHERE clause as we need to read all the data, aggregate it, then apply a filter unlike WHERE clause which filters the data at row level and reduces the I/O by reading less data. But, sometimes we need to filter aggregated date instead of row level as like below query.
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
Above query outcomes all the rows grouped by color and size, which have the sum of ListPrice greater than 3000.
WHERE vs HAVING
The WHERE clause, provide the filtration of rows depending to the criteria provided. It simply filter the row nothing else.
The HAVING clause is used with GROUP BY clause. GROUP BY clause first groups the records and then HAVING clause is used to filter the grouped records. So HAVING clause is used with GROUP BY clause.
In performance factor in mind, the WHERE is most efficient then HAVING clause. The HAVING clause must be used if needed.
A SQL statement may contains WHERE and HAVING clause both together. Please look at the Example for better understanding.
SELECT rollnumber, studentname, Class, SUM(Marks) Marks
FROM student_Result
WHERE Class=1
GROUP BY rollnumber, Class, studentname
HAVING UPPER(ISNULL(studentname,''))='RAJA RAM'
In this case the student result table is first filtered by WHERE clause and then use the GOUP BY Clause to group the records and finally use the HAVING clause to filter the student name.
The WHERE clause, provide the filtration of rows depending to the criteria provided. It simply filter the row nothing else.
The HAVING clause is used with GROUP BY clause. GROUP BY clause first groups the records and then HAVING clause is used to filter the grouped records. So HAVING clause is used with GROUP BY clause.
In performance factor in mind, the WHERE is most efficient then HAVING clause. The HAVING clause must be used if needed.
A SQL statement may contains WHERE and HAVING clause both together. Please look at the Example for better understanding.
SELECT rollnumber, studentname, Class, SUM(Marks) Marks
FROM student_Result
WHERE Class=1
GROUP BY rollnumber, Class, studentname
HAVING UPPER(ISNULL(studentname,''))='RAJA RAM'
In this case the student result table is first filtered by WHERE clause and then use the GOUP BY Clause to group the records and finally use the HAVING clause to filter the student name.
ORDER BY clause
ORDER BY clause is used to sort the output. We can use single or multiple columns to order the result set. Have a look on below sample queries:
ORDER BY clause is used to sort the output. We can use single or multiple columns to order the result set. Have a look on below sample queries:
--Order the result set by TotalListPrice in ascending order
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
ORDER BY TotalListPrice ASC
--Order the result set by TotalListPrice in descending order
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
ORDER BY TotalListPrice DESC
--Order the result set by TotalListPrice in dscending then by Size in descending and then by Color ascending
SELECT Color, Size, SUM(ListPrice) AS TotalListPrice FROM Production.Product WHERE Color = 'Black' OR Color = 'Blue'
GROUP BY Color, Size
HAVING SUM(ListPrice) > 3000
ORDER BY TotalListPrice DESC, Size DESC, Color ASC
--List of products order by product name, default in ascending order
SELECT Name
FROM Production.Product
ORDER BY Name
--List of products order by product ID, default in ascending order
SELECT ProductID, Name AS ProductName
FROM Production.Product
ORDER BY ProductID
--List of products order by color in descending order then by product name in ascending order by default
SELECT Color, Name AS ProductName
FROM Production.Product
ORDER BY Color DESC, ProductName
To sort the result set with a column in ascending or descending order, we use ASC and DESC keywords with ORDER BY clause which defaults to ascending (ASC). That is, if we omit the ASC or DESC keyword after ORDER BY, by default, it is ASC.
ORDER BY clause and PERFORMANCE of Query
Some of my friends told me that using the ORDER BY clause decreases the performance of SQL statements. Do you believe it? Yes I am, as in such type of conditions the ORDER BY clause really decrease the performance of SQL query. But you have to understand the situations where you use or don't use the ORDER BY clause.
In Microsoft SQL Server 2005/2008, you create a table. The table contains a column of a non-Unicode data type. Additionally, the collation of the column is an SQL tertiary collation. Then, you create an index that is not unique on the column. You run a query against the table by specifying the ORDER BY clause on the column.
In this scenario, the performance of the query is slow. Additionally, if the query is executed from a cursor, the cursor is converted implicitly to a keyset cursor.
Now I am trying to illustrate the causes of the problem
This problem occurs because the query optimizer does not use the index. In the execution plan of the query, the SORT operator appears first. Then, the Compute Scalar operator that contains the TERTIARY_WEIGHTS function appears.
Some other things that we must considers.
In a tertiary collation definition, certain characters are considered equal for comparison. However, the weights of these characters are considered different when you order these characters. For example, a string comparison is not case-sensitive. However, when you use the ORDER BY clause to order these strings, uppercase characters appear before lowercase characters.
The following data types are non-Unicode data types:
char
text
varchar
The following data types are Unicode data types:
nchar
ntext
nvarchar
To perform the SORT operation on non-Unicode string expressions that are defined in an SQL tertiary collation, SQL Server 2005 requires a binary string of weights for each character in the string expression.
Some of my friends told me that using the ORDER BY clause decreases the performance of SQL statements. Do you believe it? Yes I am, as in such type of conditions the ORDER BY clause really decrease the performance of SQL query. But you have to understand the situations where you use or don't use the ORDER BY clause.
In Microsoft SQL Server 2005/2008, you create a table. The table contains a column of a non-Unicode data type. Additionally, the collation of the column is an SQL tertiary collation. Then, you create an index that is not unique on the column. You run a query against the table by specifying the ORDER BY clause on the column.
In this scenario, the performance of the query is slow. Additionally, if the query is executed from a cursor, the cursor is converted implicitly to a keyset cursor.
Now I am trying to illustrate the causes of the problem
This problem occurs because the query optimizer does not use the index. In the execution plan of the query, the SORT operator appears first. Then, the Compute Scalar operator that contains the TERTIARY_WEIGHTS function appears.
Some other things that we must considers.
In a tertiary collation definition, certain characters are considered equal for comparison. However, the weights of these characters are considered different when you order these characters. For example, a string comparison is not case-sensitive. However, when you use the ORDER BY clause to order these strings, uppercase characters appear before lowercase characters.
The following data types are non-Unicode data types:
char
text
varchar
The following data types are Unicode data types:
nchar
ntext
nvarchar
To perform the SORT operation on non-Unicode string expressions that are defined in an SQL tertiary collation, SQL Server 2005 requires a binary string of weights for each character in the string expression.
NOT IN clause is a Performance Killer
Performance is a very important factor in terms of web based applications. Sometimes I find that the developer use the NOT IN clause in SQL statement which decrease the performance of entire SQL statements. Developers told that we don't have any options rater then it.
My suggestion is that, do not use the NOT IN clause in WHERE statements, instead use the NOT EXISTS statements which definitely increase the performance of your query.
To illustrate my points, I am providing you a simple example of SQL statements.
SELECT *
FROM tableA
WHERE tableA.tableBKey NOT IN (SELECT tableBKey
FROM tableB
WHERE fieldB1='something');
The above SQL statement is a performance Killer.
You can alter these statements like this to increase the real performance of SQL statement.
SELECT *
FROM tableA
WHERE NOT EXISTS( SELECT 1
FROM tableB
WHERE tableBKey = tableA.tableBKey
AND fieldB1 = 'something')
Performance is a very important factor in terms of web based applications. Sometimes I find that the developer use the NOT IN clause in SQL statement which decrease the performance of entire SQL statements. Developers told that we don't have any options rater then it.
My suggestion is that, do not use the NOT IN clause in WHERE statements, instead use the NOT EXISTS statements which definitely increase the performance of your query.
To illustrate my points, I am providing you a simple example of SQL statements.
SELECT *
FROM tableA
WHERE tableA.tableBKey NOT IN (SELECT tableBKey
FROM tableB
WHERE fieldB1='something');
The above SQL statement is a performance Killer.
You can alter these statements like this to increase the real performance of SQL statement.
SELECT *
FROM tableA
WHERE NOT EXISTS( SELECT 1
FROM tableB
WHERE tableBKey = tableA.tableBKey
AND fieldB1 = 'something')
“IN”, “EXISTS” clause and their performance
To improve the performance of the Query, the general guideline is not to prefer the "IN" Clause. The guideline of the MS SQL query performance says that if we needs "IN" clause, instead of using "IN" clause we must use the "EXISTS" clause. As the "EXISTS" clause improve the performance of the query.
Is "IN" and "EXISTS" clause are same
IN Clause
To improve the performance of the Query, the general guideline is not to prefer the "IN" Clause. The guideline of the MS SQL query performance says that if we needs "IN" clause, instead of using "IN" clause we must use the "EXISTS" clause. As the "EXISTS" clause improve the performance of the query.
Is "IN" and "EXISTS" clause are same
IN Clause
Returns true if a specified value matches any value in a sub query or a list.
EXISTS Clause
Returns true if a sub query contains any rows.
So we see that the "IN" and the "EXISTS" clause are not same. To support the above definition lets takes an example.
-- Base Tabe
IF OBJECT_ID('emp_DtlTbl') IS NOT NULL
BEGIN
DROP TABLE emp_DtlTbl;
END
GO
IF OBJECT_ID('emp_GradeTbl') IS NOT NULL
BEGIN
DROP TABLE emp_GradeTbl;
END
GO
CREATE TABLE emp_DtlTbl
(EMPID INT NOT NULL IDENTITY PRIMARY KEY,
EMPNAME VARCHAR(50)NOT NULL);
GO
CREATE TABLE emp_GradeTbl
(EMPID INT NOT NULL IDENTITY PRIMARY KEY,
GRADE VARCHAR(1) NOT NULL);
GO
-- Insert Records
INSERT INTO emp_DtlTbl
(EMPNAME)
VALUES ('Joydeep Das'), ('Sukamal Jana'), ('Sudip Das');
GO
INSERT INTO emp_GradeTbl
(GRADE)
VALUES ('B'), ('B'), ('A');
GO
-- [ IN ] Clause Example-1
SELECT *
FROM emp_DtlTbl;
WHERE EMPID IN(SELECT EMPID FROM emp_DtlTbl);
-- [ IN ] Clause Example-2
SELECT *
FROM emp_DtlTbl
WHERE EMPID IN(1,2,3);
-- [ EXISTS ] Clause Example
SELECT a.*
FROM emp_DtlTbl a
WHERE EXISTS(SELECT b.*
FROM emp_DtlTbl b
WHERE b.EMPID = a.EMPID);
Performance Factors
To understand the performance factors let see the actual execution plan for "IN" and "EXISTS" clauses.
Take this example:
-- [ IN ] Clause Example
SELECT *
FROM emp_DtlTbl
WHERE EMPID =(SELECT EMPID
FROM emp_DtlTbl
WHERE EMPID = 2);
-- [ EXISTS ] Clause Example
SELECT a.*
FROM emp_DtlTbl a
WHERE EXISTS(SELECT b.*
FROM emp_DtlTbl b
WHERE b.EMPID = 2
AND b.EMPID = a.EMPID);
If we compare the total query costs of the both MS SQL query, we see that the IN clause query cost is higher than the EXISTS clause query costs.
Special notes
Please note that: Here the data of the table is limited, so we cannot measure the performance factors.
Over clause can be used in association with aggregate function and ranking function. The over clause determine the partitioning and ordering of the records before associating with aggregate or ranking function.
Over by clause along with aggregate function can help us to resolve many issues in simpler way. Below is a sample of Over clause along with the aggregate function.
SELECT
SalesOrderID
,p.Name AS ProductName
,OrderQty
,SUM(OrderQty) OVER(PARTITION BY SalesOrderID) AS TotalOrderQty
,AVG(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Avg Qty of Item" ,COUNT(OrderQty)OVER(PARTITION BY SalesOrderID) AS "Total Number of Item"
,MIN(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Min order Qty"
,MAX(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Max Order Qty"
FROM Sales.SalesOrderDetail SOD INNER JOIN Production.Product p ON SOD.ProductID=p.ProductID WHERE SalesOrderID IN(43659,43664)
Over by clause along with aggregate function can help us to resolve many issues in simpler way. Below is a sample of Over clause along with the aggregate function.
- The difference between group by and this method is , in group by we will get only the summery part.
- We can use the over clause with out partition clause which will do an aggregation on entire result set .
- ROW_NUMBER, RANK, DENSE_RANK and NTILE are the ranking function which can be used along with Over clause.
SELECT
SalesOrderID
,p.Name AS ProductName
,OrderQty
,SUM(OrderQty) OVER(PARTITION BY SalesOrderID) AS TotalOrderQty
,AVG(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Avg Qty of Item" ,COUNT(OrderQty)OVER(PARTITION BY SalesOrderID) AS "Total Number of Item"
,MIN(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Min order Qty"
,MAX(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Max Order Qty"
FROM Sales.SalesOrderDetail SOD INNER JOIN Production.Product p ON SOD.ProductID=p.ProductID WHERE SalesOrderID IN(43659,43664)
The SQL Server (Transact-SQL) SELECT INTO statement is used to create a table from an existing table by copying the existing table's columns.
- It is important to note that when creating a table in this way, the new table will be populated with the records from the existing table (based on the SELECT Statement).
Syntax:
SELECT Column(S) INTO NewTableName FROM TableName
SELECT * INTO NewTableName FROM TableName
If you want to create only structure of table the follow the below syntax:
SELECT * INTO NewTableName FROM TableName WHERE 1=0
BETWEEN Clause Vs [ >= AND <= ]
In this article I am trying to discuss related to BETWEEN clause and >= AND <= comparisons operators and which one is best.
What is the Difference
Let's take an example to understand it properly.
Step-1 [ Create the Base Table ]
CREATE TABLE my_TestTab
(ID INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
VAL DATETIME NOT NULL);
Step-2 [ Inserting Records ]
INSERT INTO my_TestTab
(VAL)
VALUES('05-01-2012'),
('05-07-2012'),
('05-11-2012'),
('05-15-2012'),
('05-22-2012'),
('05-23-2012'),
('05-25-2012'),
('05-27-2012'),
('05-28-2012');
Step-3 [ Now use Between Clause ]
SELECT *
FROM my_TestTab
WHERE VAL BETWEEN '05-01-2012' AND '05-28-2012';
Output:
ID VAL
1 2012-05-01 00:00:00.000
2 2012-05-07 00:00:00.000
3 2012-05-11 00:00:00.000
4 2012-05-15 00:00:00.000
5 2012-05-22 00:00:00.000
6 2012-05-23 00:00:00.000
7 2012-05-25 00:00:00.000
8 2012-05-27 00:00:00.000
9 2012-05-28 00:00:00.000
Step-4 [ Now using >= AND <= ]
SELECT *
FROM my_TestTab
WHERE VAL >='05-01-2012' AND VAL<='05-28-2012';
Output:
ID VAL
1 2012-05-01 00:00:00.000
2 2012-05-07 00:00:00.000
3 2012-05-11 00:00:00.000
4 2012-05-15 00:00:00.000
5 2012-05-22 00:00:00.000
6 2012-05-23 00:00:00.000
7 2012-05-25 00:00:00.000
8 2012-05-27 00:00:00.000
9 2012-05-28 00:00:00.000
To observe the difference between Step-3 and Step-4 just execute the SQL of Step-3 Again and see the actual execution plan.
SELECT *
FROM my_TestTab
WHERE VAL BETWEEN '05-01-2012' AND '05-28-2012';

If we see the execution plan we find that
SELECT * FROM my_TestTab WHERE [VAL] >= @1 AND [VAL]<=@2
So there is no difference between Step-3 and Step-4. Actually internally the BETWEEN clause is converted to >= and <= logical operators.
Summary
As per me using BETWEEN clause is much easier then the >= and <= operators and it looks great in complex query.
It actually depends on developer and there writing style of T-SQL.
Commenting code in T-SQL:
In T-SQL, we can use double hyphens (–) to comment a single line of code (as we did in the above example code) and to comment multiple line at once we can simply enclose the codes between (/* and */) as:
/*Commented code goes here*/
SELECT 'Welcome to t-sql programming' AS [Column1]
Note:
<schema-name>.<table-name>
<schema-name> is the name of the schema and <table-name> is the name of the table. Mind the DOT (.) operator between schema name and table name. E.g. FROM [HumanResources].[Employee].
<filter> Filter is used to include only those rows from the table which are satisfying the given filter criteria. We can have multiple filters combined with AND and ORoperators. E.g. WHERE [column-name-1] = ‘some value’ AND [column-name-2] = ‘some value’ AND [column-name-3] = ‘some value’.
<filter> Filter is used to include only those rows from the table which are satisfying the given filter criteria. We can have multiple filters combined with AND and ORoperators. E.g. WHERE [column-name-1] = ‘some value’ AND [column-name-2] = ‘some value’ AND [column-name-3] = ‘some value’.
<aggregate-filter> Aggregate filter applies to aggregated data unlike “WHERE” which filters the data while reading from the table. We can use aggregated filters with the aggregated result set. E.g. HAVING COUNT(column-name-1) > 10.